Yes, could be that 45 criteria is too many for one prompt. Maybe breaking classification tasks into smaller batches reduces cognitive load and improves accuracy. LLMs have limited "working memory" during inference and evaluating 45 decisions + reasoning strains their ability to maintain consistency.
Try chunking:
First option to try:
Pass 1: Run 10-15 high-priority criteria
Pass 2: Run 10-15 organizational criteria
Pass 3: Run remaining criteria
Orchestrate this with Scope actions in Power Automate or use parallel branches if the criteria are independent.
Second option you could try:
Run the same prompt 3 times and take the majority vote for each criterion
Use a Apply to each to invoke the AI action 3 times
Parse the three JSON responses
For each criterion, assign 1 if at least 2 out of 3 responses agree
Third option to try:
Instead of asking the AI to both analyze and score in one step:
Pass 1: Extract relevant text snippets for each criterion
Pass 2: Score each criterion based on the extracted text
This separates retrieval from reasoning and could improving reliability
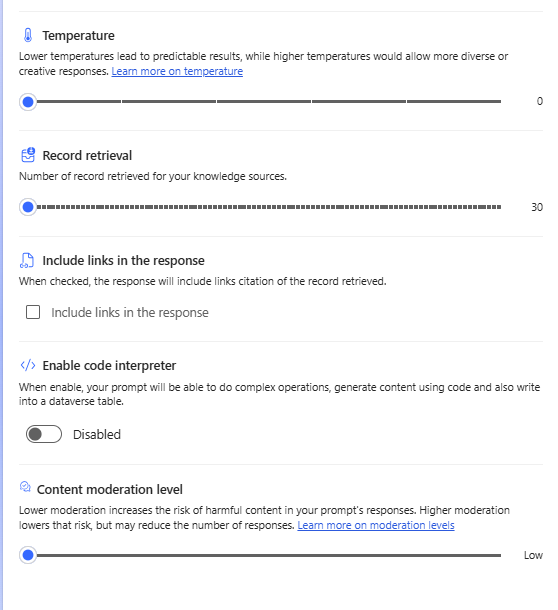
Also please verify:
Temperature is set to 0
Content moderation level is set to low
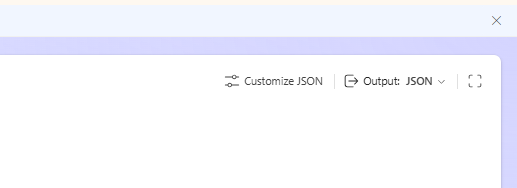
And if you haven't already: Use JSON mode in your Prompt. Define a strict JSON schema by using the Customize JSON.
Even with GPT-5 reasoning models, variability is inherent to LLM behavior.
Hope it helps!



