
Have a lot of PDFs made up of multiple documents? Want to automatically split those PDFs into their component documents?
Try this template AI Builder & GPT flow!
Go from something like this combined purchase order, invoice, & packing list file...
To these split up, component files...
Import & Set-Up
Find & download the Solution import package at the bottom of this main post. Go to the Power Apps home page (https://make.powerapps.com/). Select Solutions on the left-side menu, select Import solution, Browse your files & select the SplitPDFByComponentDocuments_1_0_0_xx.zip file you just downloaded. Then select Next & follow the menu prompts to apply or create the required connections for the solution flows. And finish importing the solution.
Once the solution is done importing, select the solution name in the list at the center of the screen. Once inside the solution click on the 3 vertical dots next to the flow name & select edit.
Once inside the flow should look like this
Assuming we want to test things out with some files in OneDrive we can first will go to the Get file content action and choose a sample file.
Then we can go to the Create text with GPT action where we will want to adjust the prompt to fit our use-case. My initial demo use-case was for a logistics order, so you will likely want to change the references to Purchase Orders, Invoices, Packing Lists, FCRs, & PODs to better match the types of component documents you may find in your PDF files.
The file provided is a combination of multiple documents. We want to get information on each component document like what document it is and what pages it is on.
Please output a JSON array where each object in the JSON array represents each component document found in the combined file. Each object should list the FileType (what document the component document is), FileIndex (the page range of the combined document the component document is on if the 1st page of the combined document is 1, which may differ from page numbering explicitly listed on each page), and ObjectIndex (the index of the JSON object in the output JSON array starting from 0).
FileTypes may be "Purchase Order", "Invoice", "Packing List", "Forwarder Certificate of Receipt", "Proof of Delivery", or "Other".
Example output JSON when a combined file's page 1 is a Purchase Order, pages 2-5 are an Invoice, & remaining pages are some document Other than the options explicitly outlined above...
[
{
"FileType": "Purchase Order"
"FileIndex": "[1-1]"
"ObjectIndex": 0
},
{
"FileType": "Invoice"
"FileIndex": "[2-5]"
"ObjectIndex": 1
},
{
"FileType": "Other"
"FileIndex": "[6-9]"
"ObjectIndex": 2
}
]
So all the yellow-highlighted pieces above will likely need to change to fit your use-case.
Next we have the Select PageSplits which will take the FileIndex fields from the GPT output array & format them so they can be used to form a list of page splits for the Split Configuration in the Encodian action.
Speaking of the Encodian action, this is where you will want to create a new action & add the Encodian PDF - Split action. To use Encoidan actions you will need to fill this form (
https://www.encodian.com/product/flowr/#pre-anchor-form) to get an API key. You can then create a connection with the API key they send you in an email. On the Free tier you will get 50 free actions like Split PDF per month & 10,000 actions per month if you upgrade to standard tier.
From there you can then transfer the inputs from the placeholder "Add Encodian PDF - Split action here" action to the actual Encodian action.
Then in the "Split Documents Output" action you will want to replace the placeholder sample data with the dynamic content for the split output document contents array outputs('PDF_-_Split')?['body']?['documents']
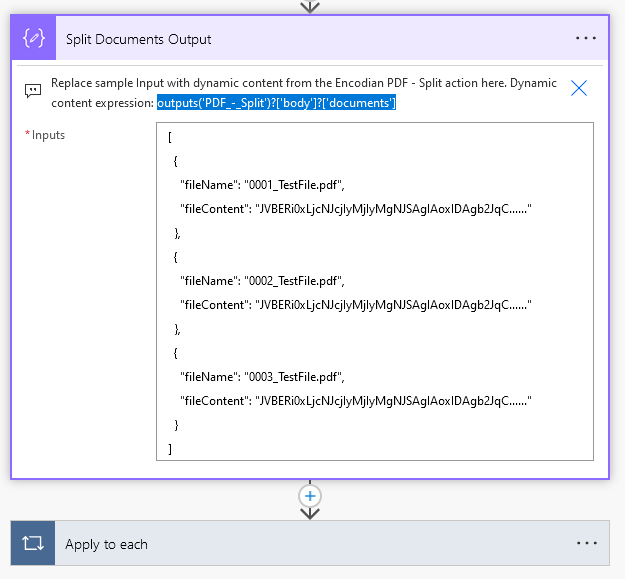
After that we can open the Apply to each & Switch actions to see how we are routing the GPT output information & associated document contents based on their file-type. Here we can see the Apply to each is acting on the component document output array of the GPT action. The switch creates different branches for each type of file. And because the PDF - Split array of document contents is in the order the component documents appear in the original PDF file, we can use the ObjectIndex of the GPT component document information array as a number selector in the array of PDF - Split document contents to grab the correct document contents for the current Apply to each item. Note you must change the Swtich FileType Cases/Equals inputs to exactly match the FileType options you specified in the GPT prompt.
And that's all the set-up to split PDFs into their component documents using AI Builder & non-premium 3rd party actions like Encodian.



