Merge PDFs, split PDFs by page, & split PDFs by text found on pages without any 3rd party connectors.
There are 3rd party connectors like Adobe & Encodian to merge or split PDFs, but some organizations would prefer the data security, privacy, & lower cost of a Microsoft solution for merging or splitting PDFs. This template provides such a solution using HTTP calls to an Azure Function that uses the Python libraries to merge or split PDFs. Also with higher volume workloads, performing say 20,000 pdf actions per month using a service like Encodian would cost more than $80 per month, whereas an Azure Function would cost less than 40 cents for 20,000 actions, plus $15 per month if you do not already have a premium Power Automate license.
Version 2.2 now available. Now with support of PDF form fields (merge_pdf_fitz works better for merging PDFs with form fields & 'split_pdf_fitz' works better for splitting PDFs with form fields).
Flow Preview
Import & Set-Up
Find & download the Solution import package at the bottom of this main post.
Go to the Power Apps home page (https://make.powerapps.com/). Select Solutions on the left-side menu, select Import solution, Browse your files & select the MergeAndSplitPDFs_1_0_0_xx.zip file you just downloaded. Then select Next & follow the menu prompts to apply or create the required connections for the solution flows. And finish importing the solution.
Once the solution is done importing, select the solution name in the list at the center of the screen. Once inside the solution click on the 3 vertical dots next to the flow name & select edit.
Now that the flow is imported & open, we need to set up the Azure Function used for the Page Split, Text Split, & Merge HTTP calls.
If you have already worked with and deployed Azure Functions before, then you can skip the extra installations.
If you haven't deployed Azure Functions, you can go to the Microsoft Store & make sure you have VS Code & Python installed.
Once VS Code is installed, open it. Go to the 4 blocks on the left side menu to open the list of extensions. Search for Azure in the extensions & select to install Azure Functions. Azure Account & Azure Resources will automatically be installed too.
Once all the extensions are installed, go to the Azure A on the left side menu & select to sign in to Azure.
Next set up a project folder on your machine for Azure Functions & a sub-folder for this Merge And Split project.
Back in VS Code select the button to create a new Azure Function. Follow the Function set-up instructions selecting the Merge And Split project folder you just created, Python language Model V2, and where in VS Code to open the new Azure Function project.
Once all the project files are loaded in VS Code, select the function_app.py file. Remove all the code in the file. Go back to the tab with the flow, open the "Azure Function Python Script" action, copy its contents & paste them into the function_app.py file in VS Code. Cntrl+S / Save the file.
Next go to the requirements.txt file. Go to the flow to the "Azure Function Requirements.txt" action & copy its contents. Paste the contents into the requirements.txt file in VS Code. Cntrl+S / Save the file.
Go back to the Azure A on the left-side menu. Select the Deploy function button. Select Create New in the list of function. Follow the menus/prompts to create a new function. (If Create New doesn't appear, you may have to log in to Azure, navigate to Azure Functions & go through the process to create a new function so the new function will appear in the list of function options to deploy to.)
Go to Azure & login. Go to Function App. Find & select the newly deployed function. Select the split function you want to use under Name (the split_pdf_fitz function supports a wider range of pdfs). Select Get function URL & in the pop-up menu & copy the Function key url.
Paste the function URL into the URI input of each of the split HTTP actions.
Then back on your Azure tab back out to the merge-and-split-pdfs function app menu & navigate to the merge function you want to use under Name (the merge_pdf_fitz function supports a wider range of pdfs). Select Get function URL & in the pop-up menu & copy the Function key url. Paste the function URL into the URI of the merge HTTP action.
Each HTTP action has a Content parameter for the Body that takes the content block from any of the Get file content actions. The content block that looks like...
{
"$content-type": "application/pdf",
"$content": "AbC123..."
}
No need to isolate the base64 in $content, it takes the whole block.
And each HTTP action also returns a similar content block or an array of content blocks as the Body of its outputs (MERGE calls should return a single content block & SPLIT calls should return an array with a content block for each split of PDF pages). These content blocks can feed directly into Create file, Attachment, and other actions.
The Page split requires the pages parameter to be present & to be an array of page numbers to split on. Splits start at the start of the page listed & end 1 page before the next page # listed.
The Text split requires the split_text parameter to be present & to be a text string to search for on each page to determine where to split. Splits start at the start of the page where the chosen text is found & end 1 page before the next page where the text is found.
For Merge pdfs, files are merged in the order they are present in the Content input array. Note you can manually create a Content array by inserting a comma-separated list of content blocks between array square brackets [ ], or if you already have an array of file content blocks then you can just put the dynamic content for that array in the Content parameter input.
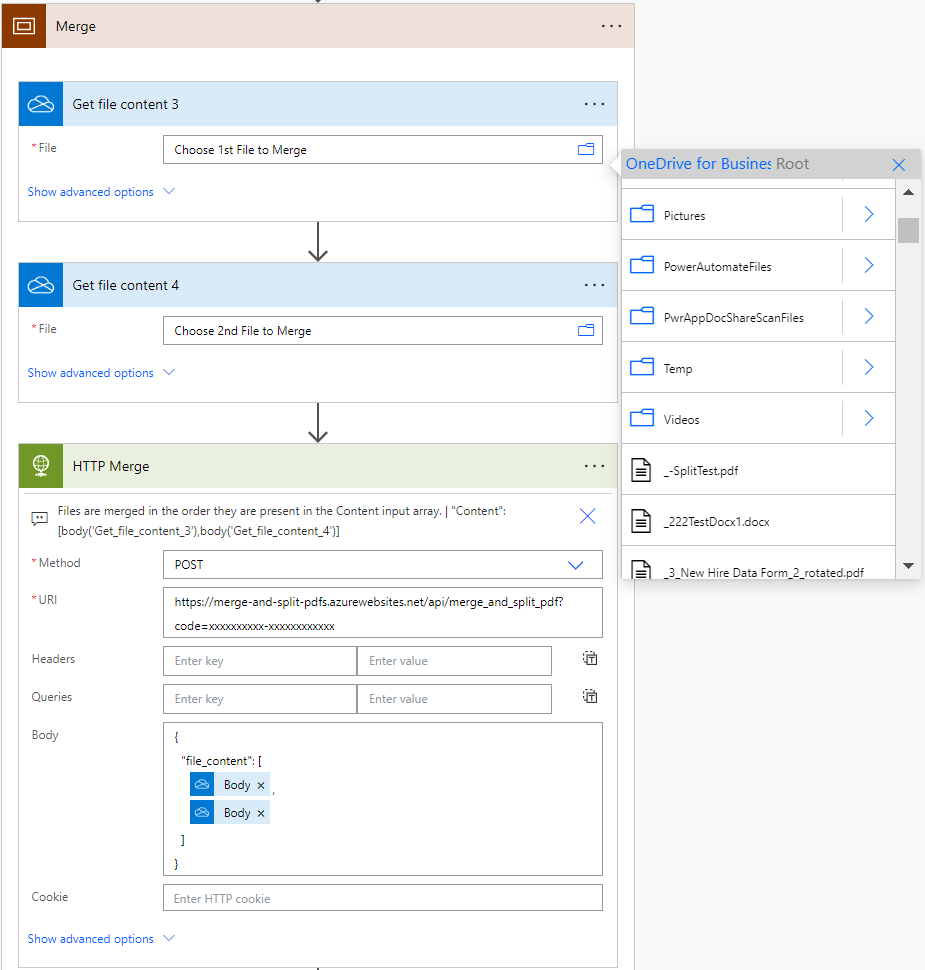
The flow is set up so you can test things out with some OneDrive files, but once you are comfortable with how things work, then you can copy & paste the actions into any of your flows where you need to merge or split PDF files.
These functions & many other functions are available in one big import on the
File & Utility Functions page along with a template Power Automate flow showing how to use most of them. I recommend following the instructions to import that full package of functions & example flow.
But if for some reason you just want to get the functions shown in this thread...
Version 2.2
-Reorganizes the merge & the split operations into different sub-functions inside the function app. So you can now just use different HTTP URIs to call the different merge or split operations without needing to add a "Operation" parameter to the call bodies.
-Adds new support for pdfs with form fields (merge_pdf_fitz works better for merging PDFs with form fields & 'split_pdf_fitz' works better for splitting PDFs with form fields).
-Adds a sub-function to detect if a pdf has a text layer which may be useful as the split by text function only works on pdfs with text-layers, it does not work on scanned-image pdfs.
Code For Manual Set-Up...
Requirements.txt:
azure-functions
PyMuPDF==1.25.3
PyPDF2==3.0.1
Azure Function Python Code:
import azure.functions as func
import logging
import json
import base64
import fitz
from io import BytesIO
import traceback
from PyPDF2 import PdfReader, PdfWriter
from PyPDF2.generic import TextStringObject
from PyPDF2.generic import DictionaryObject, NameObject, BooleanObject, ArrayObject
from collections import defaultdict
app = func.FunctionApp(http_auth_level=func.AuthLevel.FUNCTION)
@app.route(route="detect_pdf_text_layer")
def detect_pdf_text_layer(req: func.HttpRequest) -> func.HttpResponse:
try:
req_json = req.get_json()
pdf_bytes = base64_to_pdf(req_json['file_content'].get('$content'))
text_layer, all_pages_text_layer = pdf_text_layer_info(pdf_bytes)
response_data = {
"text_layer": text_layer,
"all_pages_text_layer": all_pages_text_layer
}
return func.HttpResponse(
body=json.dumps(response_data),
mimetype="application/json",
status_code=200
)
except Exception as e:
return func.HttpResponse(str(e), status_code=400)
def base64_to_pdf(base64_string):
file_bytes = base64.b64decode(base64_string)
if file_bytes[0:4] != b"%PDF":
raise ValueError("Missing the PDF file signature")
return file_bytes
def pdf_text_layer_info(pdf_bytes: bytes) -> tuple:
"""
Check if any page in the PDF contains a text layer and if all pages have a text layer.
Returns (text_layer_found, all_pages_have_text_layer).
"""
pdf_document = fitz.open(stream=pdf_bytes, filetype="pdf")
any_text_layer = False
all_text_layer = True
for page_num in range(len(pdf_document)):
page = pdf_document.load_page(page_num)
text = page.get_text()
if text.strip():
any_text_layer = True
else:
all_text_layer = False
return any_text_layer, all_text_layer
@app.route(route="merge_pdf_pypdf2")
def merge_pdf_pypdf2(req: func.HttpRequest) -> func.HttpResponse:
try:
pdf_base64_strings_list = [item.get('$content') for item in req.get_json()['file_content']]
merged_pdf_base64_string = merge_pdfs(pdf_base64_strings_list)
return func.HttpResponse(
body=json.dumps({
"$content-type": "application/pdf",
"$content": merged_pdf_base64_string
}),
mimetype="application/json",
status_code=200
)
except Exception as e:
return func.HttpResponse(f"Error: {str(e)}", status_code=500)
def base64_to_pdf(base64_string):
file_bytes = base64.b64decode(base64_string)
if file_bytes[0:4] != b"%PDF":
raise ValueError("Missing the PDF file signature")
return BytesIO(file_bytes)
def merge_pdfs(pdf_base64_list):
"""
Merge multiple PDFs (with form fields) and preserve all fields:
- text fields
- checkboxes
- single-select (radio) buttons
"""
writer = PdfWriter()
all_fields = ArrayObject()
found_form = False
for pdf_b64 in pdf_base64_list:
pdf_stream = base64_to_pdf(pdf_b64)
if not isinstance(pdf_stream, BytesIO):
pdf_stream = BytesIO(pdf_stream)
pdf_stream.seek(0)
reader = PdfReader(pdf_stream)
for page in reader.pages:
writer.add_page(page)
root = reader.trailer["/Root"]
if "/AcroForm" in root:
found_form = True
acroform = root["/AcroForm"]
if "/Fields" in acroform:
for f in acroform["/Fields"]:
all_fields.append(f)
if found_form and len(all_fields) > 0:
final_acroform = DictionaryObject()
final_acroform[NameObject("/Fields")] = all_fields
final_acroform[NameObject("/NeedAppearances")] = BooleanObject(True)
writer._root_object[NameObject("/AcroForm")] = final_acroform
merged_pdf_io = BytesIO()
writer.write(merged_pdf_io)
merged_pdf_io.seek(0)
return base64.b64encode(merged_pdf_io.read()).decode("utf-8")
@app.route(route="merge_pdf_fitz")
def merge_pdf_fitz(req: func.HttpRequest) -> func.HttpResponse:
try:
pdf_base64_strings_list = [item.get('$content') for item in req.get_json()['file_content']]
merged_pdf_base64_string = merge_pdfs(pdf_base64_strings_list)
return func.HttpResponse(
body=json.dumps({
"$content-type": "application/pdf",
"$content": merged_pdf_base64_string
}),
mimetype="application/json",
status_code=200
)
except Exception as e:
debug_error = logging.exception(f"An error occurred: {str(e)}\n\nTraceback:\n{traceback.format_exc()}")
return func.HttpResponse(
f"Error: {str(e)}\n\nTraceback:\n{traceback.format_exc()}",
status_code=500
)
def base64_to_pdf(base64_string):
file_bytes = base64.b64decode(base64_string, validate=True)
if file_bytes[0:4] != b"%PDF":
raise ValueError("Missing the PDF file signature")
return file_bytes
def merge_pdfs(pdf_base64_list):
result = fitz.open()
all_form_values = {}
for pdf_base64 in pdf_base64_list:
pdf_bytes = base64_to_pdf(pdf_base64)
with fitz.open(stream=pdf_bytes, filetype="pdf") as doc:
field_data = {}
for page in doc:
for widget in page.widgets():
if widget.field_name:
if widget.field_type == fitz.PDF_WIDGET_TYPE_RADIOBUTTON:
if hasattr(widget, 'field_flags') and (widget.field_flags & 2**15):
field_data[widget.field_name] = widget.field_value
else:
field_data[widget.field_name] = widget.field_value
all_form_values.update(field_data)
for pdf_base64 in pdf_base64_list:
pdf_bytes = base64.b64decode(pdf_base64)
with fitz.open(stream=pdf_bytes, filetype="pdf") as doc:
result.insert_pdf(doc, annots=True)
processed_fields = set()
for page in result:
for widget in page.widgets():
field_name = widget.field_name
if field_name in all_form_values and field_name not in processed_fields:
try:
if widget.field_type == fitz.PDF_WIDGET_TYPE_RADIOBUTTON:
radio_group_name = field_name
if radio_group_name in processed_fields:
continue
target_value = all_form_values.get(radio_group_name)
if not target_value:
continue
try:
result.set_field_value(radio_group_name, target_value)
except AttributeError:
continue
processed_fields.add(radio_group_name)
else:
widget.field_value = all_form_values[field_name]
widget.update()
processed_fields.add(field_name)
except Exception as e:
pass
buffer = BytesIO()
result.save(
buffer,
garbage=0,
deflate=True,
clean=False
)
buffer.seek(0)
merged_pdf_bytes = buffer.read()
return base64.b64encode(merged_pdf_bytes).decode("utf-8")
@app.route(route="split_pdf_pypdf2")
def split_pdf_pypdf2(req: func.HttpRequest) -> func.HttpResponse:
try:
req_json = req.get_json()
pdf_bytes = base64_to_pdf(req_json['file_content'].get('$content'))
page_numbers = req_json.get('pages')
split_text = req_json.get('split_text')
if page_numbers:
split_base64_strings = split_pdf_by_page_numbers(pdf_bytes, page_numbers)
elif split_text:
if pdf_has_text_layer(pdf_bytes):
split_base64_strings = split_pdf_by_text(pdf_bytes, split_text)
else:
return func.HttpResponse("Method 'TEXT' does not work on pdfs that do not have text-layers. Use a different method or only use on pdfs with text-layers.", status_code=400)
else:
return func.HttpResponse("Invalid. Must provide a 'pages' array to split by page or a 'split_text' to split by exact text.", status_code=400)
response_data = [{"$content-type": "application/pdf", "$content": pdf} for pdf in split_base64_strings]
return func.HttpResponse(
body=json.dumps(response_data),
mimetype="application/json",
status_code=200
)
except Exception as e:
return func.HttpResponse(str(e), status_code=400)
def base64_to_pdf(base64_string):
file_bytes = base64.b64decode(base64_string)
if file_bytes[0:4] != b"%PDF":
raise ValueError("Missing the PDF file signature")
return file_bytes
def pdf_has_text_layer(pdf_bytes: bytes) -> bool:
"""
Check if the PDF contains a text layer.
Returns True if text is found, False otherwise.
"""
pdf_document = fitz.open(stream=pdf_bytes, filetype="pdf")
for page_num in range(len(pdf_document)):
page = pdf_document.load_page(page_num)
text = page.get_text()
if text.strip():
return True
return False
def split_pdf_by_page_numbers(pdf_bytes, page_numbers):
logging.info("Function is using split_pdf_by_page_numbers")
pdf_reader = PdfReader(BytesIO(pdf_bytes))
total_pages = len(pdf_reader.pages)
result_base64_strings = []
if page_numbers[0] != 1:
page_numbers = [1] + page_numbers
original_field_values = {}
if pdf_reader.get_fields():
for field_name, field in pdf_reader.get_fields().items():
if "/V" in field:
original_field_values[field_name] = field["/V"]
for i in range(len(page_numbers)):
start_page = page_numbers[i] - 1
end_page = page_numbers[i + 1] - 2 if i < len(page_numbers) - 1 else total_pages - 1
pdf_writer = PdfWriter()
section_fields = {}
for j in range(start_page, end_page + 1):
page = pdf_reader.pages[j]
pdf_writer.add_page(page)
if "/Annots" in page:
page_annots = page["/Annots"]
for annot_idx, annot_ref in enumerate(page_annots):
annot = annot_ref.get_object()
if annot.get("/Subtype") == "/Widget":
if "/Parent" in annot:
parent = annot["/Parent"].get_object()
if "/T" in parent:
field_name = parent["/T"]
if isinstance(field_name, TextStringObject):
section_fields[str(field_name)] = annot
elif "/T" in annot:
field_name = annot["/T"]
if isinstance(field_name, TextStringObject):
section_fields[str(field_name)] = annot
if section_fields:
acro_form = DictionaryObject()
acro_form[NameObject("/NeedAppearances")] = BooleanObject(True)
if pdf_reader.root_object.get("/AcroForm") is not None:
original_acro_form = pdf_reader.root_object["/AcroForm"]
for key in ["/DR", "/DA", "/Q", "/XFA"]:
if key in original_acro_form:
acro_form[NameObject(key)] = original_acro_form[key]
field_array = ArrayObject()
for field_name, field_ref in section_fields.items():
field_array.append(field_ref)
acro_form[NameObject("/Fields")] = field_array
pdf_writer._root_object[NameObject("/AcroForm")] = acro_form
for field_name, field_value in original_field_values.items():
if field_name in section_fields:
try:
field_obj = section_fields[field_name]
if isinstance(field_value, TextStringObject):
field_obj[NameObject("/V")] = field_value
update_dict = {field_name: field_value}
pdf_writer.update_page_form_field_values(pdf_writer.pages[0], update_dict)
except Exception as e:
logging.warning(f"Could not update field value for {field_name}: {str(e)}")
output_stream = BytesIO()
pdf_writer.write(output_stream)
output_stream.seek(0)
split_pdf_bytes = output_stream.read()
result_base64_strings.append(base64.b64encode(split_pdf_bytes).decode("utf-8"))
return result_base64_strings
def split_pdf_by_text(pdf_bytes, split_text):
logging.info("Function is using split_pdf_by_text")
pdf_reader = PdfReader(BytesIO(pdf_bytes))
result = []
current_range = []
base64_results = []
for page_num, page in enumerate(pdf_reader.pages):
page_text = page.extract_text()
if split_text in page_text:
if current_range:
result.append(current_range)
current_range = []
current_range.append(page_num)
if current_range:
result.append(current_range)
original_field_values = {}
if pdf_reader.get_fields():
for field_name, field in pdf_reader.get_fields().items():
if "/V" in field:
original_field_values[field_name] = field["/V"]
for page_range in result:
pdf_writer = PdfWriter()
section_fields = {}
for page_idx in page_range:
page = pdf_reader.pages[page_idx]
pdf_writer.add_page(page)
if "/Annots" in page:
page_annots = page["/Annots"]
for annot_idx, annot_ref in enumerate(page_annots):
annot = annot_ref.get_object()
if annot.get("/Subtype") == "/Widget":
if "/Parent" in annot:
parent = annot["/Parent"].get_object()
if "/T" in parent:
field_name = parent["/T"]
if isinstance(field_name, TextStringObject):
section_fields[str(field_name)] = annot
elif "/T" in annot:
field_name = annot["/T"]
if isinstance(field_name, TextStringObject):
section_fields[str(field_name)] = annot
if section_fields:
acro_form = DictionaryObject()
acro_form[NameObject("/NeedAppearances")] = BooleanObject(True)
if pdf_reader.root_object.get("/AcroForm") is not None:
original_acro_form = pdf_reader.root_object["/AcroForm"]
for key in ["/DR", "/DA", "/Q", "/XFA"]:
if key in original_acro_form:
acro_form[NameObject(key)] = original_acro_form[key]
field_array = ArrayObject()
for field_name, field_ref in section_fields.items():
field_array.append(field_ref)
acro_form[NameObject("/Fields")] = field_array
pdf_writer._root_object[NameObject("/AcroForm")] = acro_form
for field_name, field_value in original_field_values.items():
if field_name in section_fields:
try:
field_obj = section_fields[field_name]
if isinstance(field_value, TextStringObject):
field_obj[NameObject("/V")] = field_value
update_dict = {field_name: field_value}
pdf_writer.update_page_form_field_values(pdf_writer.pages[0], update_dict)
except Exception as e:
logging.warning(f"Could not update field value for {field_name}: {str(e)}")
output_stream = BytesIO()
pdf_writer.write(output_stream)
output_stream.seek(0)
split_pdf_bytes = output_stream.read()
base64_results.append(base64.b64encode(split_pdf_bytes).decode("utf-8"))
return base64_results
@app.route(route="split_pdf_fitz")
def split_pdf_fitz(req: func.HttpRequest) -> func.HttpResponse:
try:
req_json = req.get_json()
pdf_bytes = base64_to_pdf(req_json['file_content'].get('$content'))
page_numbers = req_json.get('pages')
split_text = req_json.get('split_text')
split_regex = req_json.get('split_regex')
if page_numbers:
split_base64_strings = split_pdf_by_page_numbers(pdf_bytes, page_numbers)
elif split_text or split_regex:
if pdf_has_text_layer(pdf_bytes):
split_base64_strings = split_pdf_by_text(pdf_bytes, split_text, split_regex)
else:
return func.HttpResponse("Text & regex methods do not work on PDFs without text layers. Use a different method or only use on PDFs with text layers.", status_code=400)
else:
return func.HttpResponse("Invalid. Must provide a 'pages' array to split by page, a 'split_text' to split by exact text, or a 'split_regex to split by text matching a regex expression.", status_code=400)
response_data = [{"$content-type": "application/pdf", "$content": pdf} for pdf in split_base64_strings]
return func.HttpResponse(
body=json.dumps(response_data),
mimetype="application/json",
status_code=200
)
except Exception as e:
logging.exception(f"An error occurred: {str(e)}\n\nTraceback:\n{traceback.format_exc()}")
return func.HttpResponse(
f"Error: {str(e)}\n\nTraceback:\n{traceback.format_exc()}",
status_code=500
)
def base64_to_pdf(base64_string):
file_bytes = base64.b64decode(base64_string, validate=True)
if file_bytes[0:4] != b"%PDF":
raise ValueError("Missing the PDF file signature")
return file_bytes
def pdf_has_text_layer(pdf_bytes: bytes) -> bool:
"""
Check if the PDF contains a text layer.
Returns True if text is found, False otherwise.
"""
pdf_document = fitz.open(stream=pdf_bytes, filetype="pdf")
has_text = False
for page_num in range(min(len(pdf_document), 3)):
page = pdf_document[page_num]
text = page.get_text()
if text.strip():
has_text = True
break
pdf_document.close()
return has_text
def pdf_has_form_fields(pdf_bytes: bytes) -> bool:
"""
Check if the PDF contains any form fields throughout the entire document.
Returns True if any form fields are found, False otherwise.
"""
pdf_document = fitz.open(stream=pdf_bytes, filetype="pdf")
has_fields = False
for page_num in range(len(pdf_document)):
page = pdf_document[page_num]
try:
widgets = page.widgets()
if len(widgets) > 0:
has_fields = True
break
except Exception as e:
logging.warning(f"Error checking for widgets on page {page_num}: {str(e)}")
try:
if "AcroForm" in pdf_document.get_pdf_catalog():
has_fields = True
except Exception as e:
logging.warning(f"Error checking for AcroForm: {str(e)}")
pdf_document.close()
return has_fields
def get_form_fields_info(pdf_bytes):
"""
Extract comprehensive form field information including all metadata.
This function creates a more detailed mapping of fields to ensure proper preservation.
"""
doc = fitz.open(stream=pdf_bytes, filetype="pdf")
page_to_fields = defaultdict(set)
field_to_pages = defaultdict(set)
field_data = {}
for page_num in range(len(doc)):
page = doc[page_num]
try:
for widget in page.widgets():
try:
field_name = widget.field_name
if field_name:
page_to_fields[page_num].add(field_name)
field_to_pages[field_name].add(page_num)
if field_name not in field_data:
field_data[field_name] = {
'value': widget.field_value if hasattr(widget, 'field_value') else None,
'type': widget.field_type if hasattr(widget, 'field_type') else None,
'flags': widget.field_flags if hasattr(widget, 'field_flags') else None,
'rect': widget.rect if hasattr(widget, 'rect') else None,
'appearance': None,
}
except Exception as e:
logging.warning(f"Error processing widget on page {page_num}: {str(e)}")
except Exception as e:
logging.warning(f"Error accessing widgets on page {page_num}: {str(e)}")
doc.close()
return page_to_fields, field_to_pages, field_data
def process_split_document(pdf_bytes, start_page, end_page):
"""
Creates a new document from the specified page range and ensures form fields are preserved.
Using a different approach to ensure consistent form field preservation across all splits.
"""
source_doc = fitz.open(stream=pdf_bytes, filetype="pdf")
new_doc = fitz.open()
new_doc.insert_pdf(source_doc, from_page=start_page, to_page=end_page, annots=True)
try:
if hasattr(source_doc, "xref_xml_metadata") and source_doc.xref_xml_metadata > 0:
if hasattr(new_doc, "set_xml_metadata") and hasattr(source_doc, "xml_metadata"):
new_doc.set_xml_metadata(source_doc.xml_metadata)
except Exception as e:
logging.warning(f"Error handling XFA forms: {str(e)}")
try:
if "AcroForm" in source_doc.get_pdf_catalog():
logging.info("AcroForm found in source document, ensuring preservation")
except Exception as e:
logging.warning(f"Error checking for AcroForm: {str(e)}")
try:
buffer = BytesIO()
new_doc.save(
buffer,
garbage=0,
deflate=True,
clean=False,
encryption=False,
permissions=int(
fitz.PDF_PERM_ACCESSIBILITY |
fitz.PDF_PERM_PRINT |
fitz.PDF_PERM_COPY |
fitz.PDF_PERM_ANNOTATE
),
preserve_annots=True,
embedded_files=True
)
buffer.seek(0)
pdf_bytes = buffer.read()
except Exception as e:
logging.warning(f"Error saving with options: {str(e)}. Using fallback method.")
try:
buffer = BytesIO()
new_doc.save(buffer, garbage=0, clean=False)
buffer.seek(0)
pdf_bytes = buffer.read()
except Exception as e2:
logging.warning(f"Fallback method also failed: {str(e2)}. Using tobytes.")
pdf_bytes = new_doc.tobytes()
new_doc.close()
source_doc.close()
return base64.b64encode(pdf_bytes).decode("utf-8")
def split_pdf_by_page_numbers(pdf_bytes, page_numbers):
"""
Split PDF by page numbers, preserving form fields and their values.
Returns a list of base64-encoded PDF documents.
"""
has_form_fields = pdf_has_form_fields(pdf_bytes)
if has_form_fields:
logging.info("PDF contains form fields - using form-preserving splitting")
doc = fitz.open(stream=pdf_bytes, filetype="pdf")
total_pages = len(doc)
doc.close()
result_base64_strings = []
if not page_numbers or page_numbers[0] != 1:
page_numbers = [1] + (page_numbers if page_numbers else [])
if page_numbers[-1] <= total_pages:
page_numbers.append(total_pages + 1)
for i in range(len(page_numbers) - 1):
start_page = page_numbers[i] - 1
end_page = page_numbers[i+1] - 2
if i == len(page_numbers) - 2:
end_page = total_pages - 1
if start_page > end_page or start_page < 0 or end_page >= total_pages:
continue
base64_pdf = process_split_document(pdf_bytes, start_page, end_page)
result_base64_strings.append(base64_pdf)
return result_base64_strings
def split_pdf_by_text(pdf_bytes, split_text=None, split_regex=None):
"""
Split PDF by exact text occurrence or regex match, preserving form fields and their values.
Returns a list of base64-encoded PDF documents.
"""
has_form_fields = pdf_has_form_fields(pdf_bytes)
if has_form_fields:
logging.info("PDF contains form fields - using form-preserving splitting")
doc = fitz.open(stream=pdf_bytes, filetype="pdf")
total_pages = len(doc)
split_pages = [0]
for page_num in range(total_pages):
page = doc[page_num]
text = page.get_text()
if split_regex:
if re.search(split_regex, text) and page_num > 0:
split_pages.append(page_num)
elif split_text:
if split_text in text and page_num > 0:
split_pages.append(page_num)
if split_pages[-1] != total_pages - 1:
split_pages.append(total_pages)
else:
split_pages.append(total_pages)
doc.close()
result_base64_strings = []
for i in range(len(split_pages) - 1):
start_page = split_pages[i]
end_page = split_pages[i + 1] - 1
if end_page < start_page:
continue
base64_pdf = process_split_document(pdf_bytes, start_page, end_page)
result_base64_strings.append(base64_pdf)
return result_base64_strings
![]()




