
Extract Data From PDFs & Images With GPT
This template uses AI Builder's OCR for PDFs & Images to extract the text present in a file, replicates the file in a text (txt) format, then passes it off to a GPT prompt action for things like data extraction.
Seems to have a 85% or greater reliability for returning requested data fields from most PDFs. It's likely good enough to do more direct data entry on some use-cases with well formatted, clean PDFs, and in many other cases it is good at doing a 1st pass on a file & providing a default / pre-fill value for fields before a person then checks & completes something with the data.
It does not require training on different formats, styles, wording, etc. It works on multiple pages at once. And you can always adjust the prompt to extract the different data you want on different documents & adjust how you want the data to be represented in the output.
It also...
-Runs in less than a minute, usually 10-35 seconds, so it can respond in time for a Power Apps call.
-Handles 10-20 document pages at a time given the recent Create text with GPT update to a 16k model.
-Does not use additional 3rd party services, maintaining better data privacy.

Full Flow:
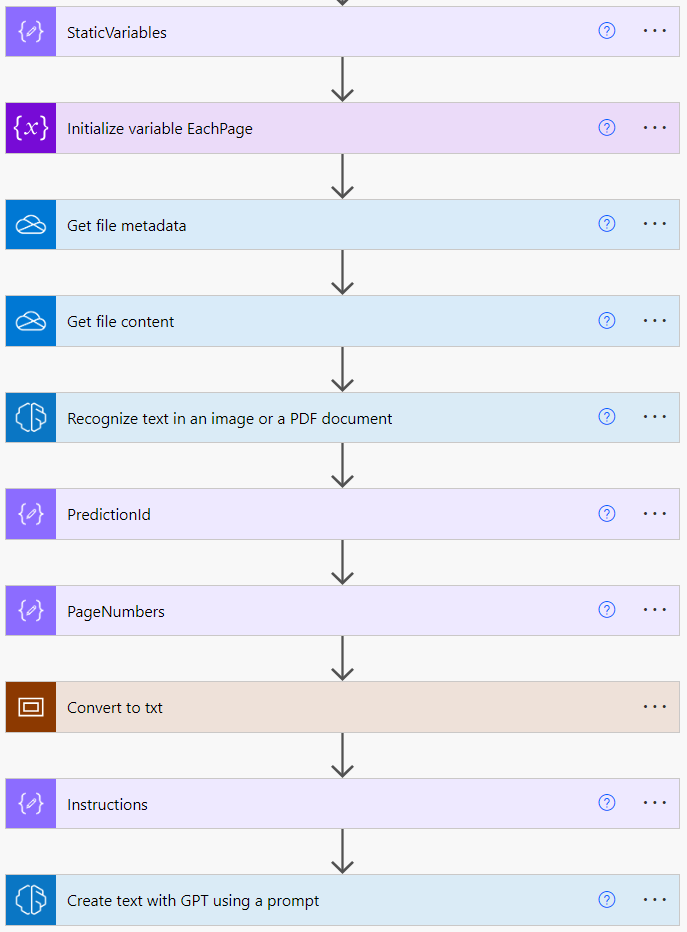
The AI Builder Recognize text action returns a JSON array of each piece of text found in the PDF or image.
The Convert to txt loop goes through each horizontal line in the PDF or image & creates a line of text to approximately match both the text & spacing between text for that line.
Each vertical line of text is then combined into a single block of text like a big txt file in the final Compose action, before it is then passed to GPT through the AI Builder Create text action.
Example
Demonstration Invoice Example...

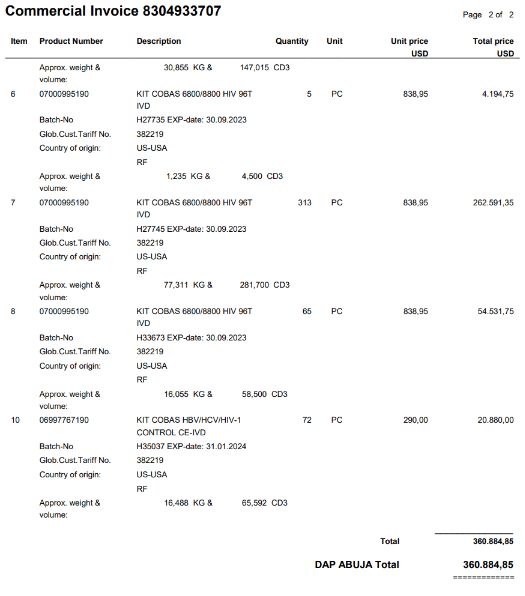
The AI Builder action uses optical character recognition (OCR) on this invoice PDF to return each piece of text & its associated x, y coordinates.
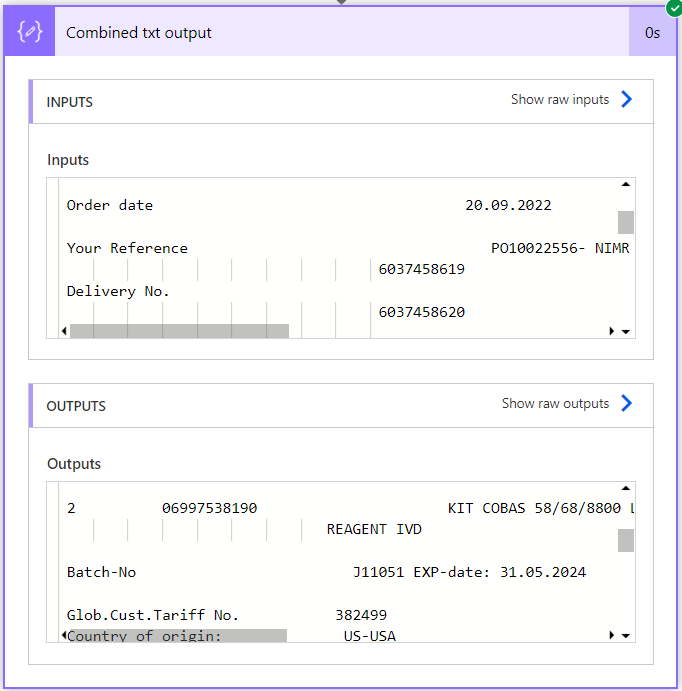
Then the Convert to txt loop produces this output shown in the final Compose...
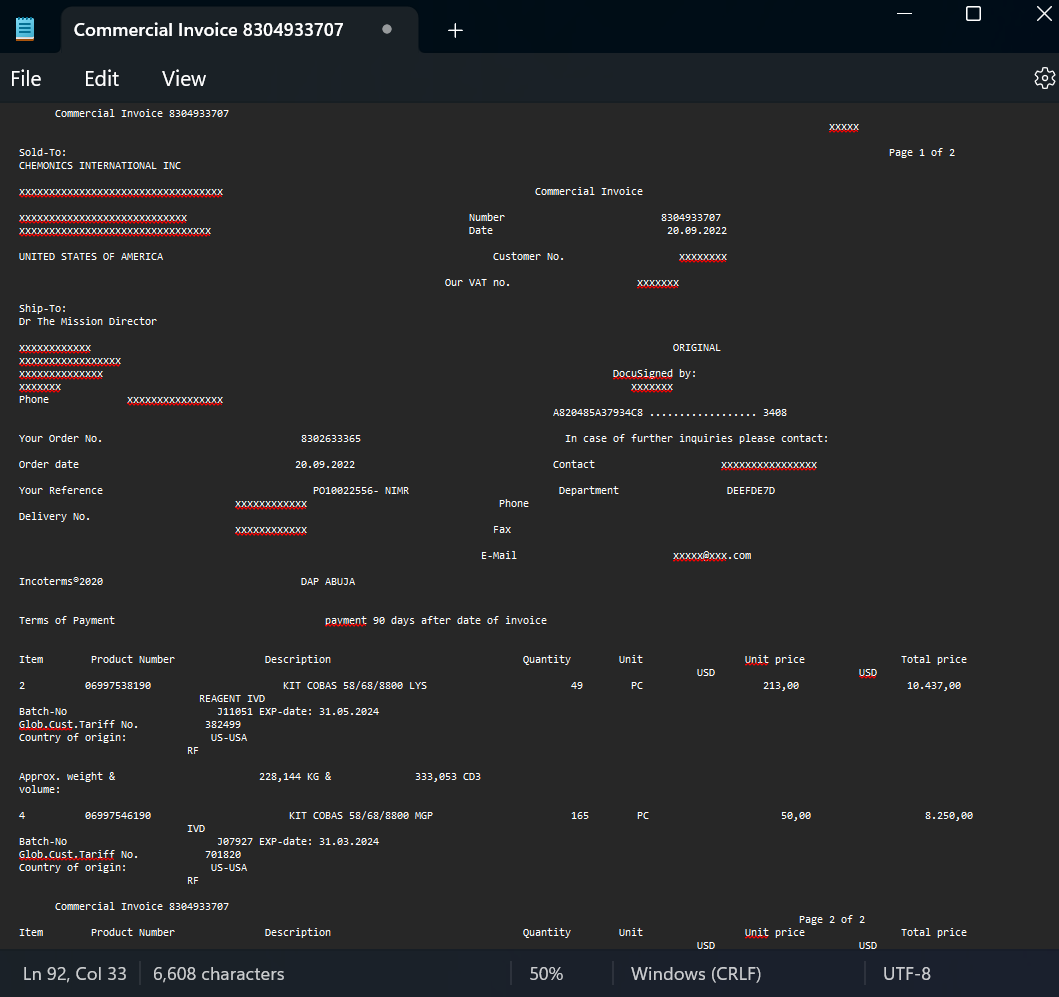
And if we copy that output over to a text (txt) notebook, then this is what it looks like...
That is then fed into this GPT action prompt...
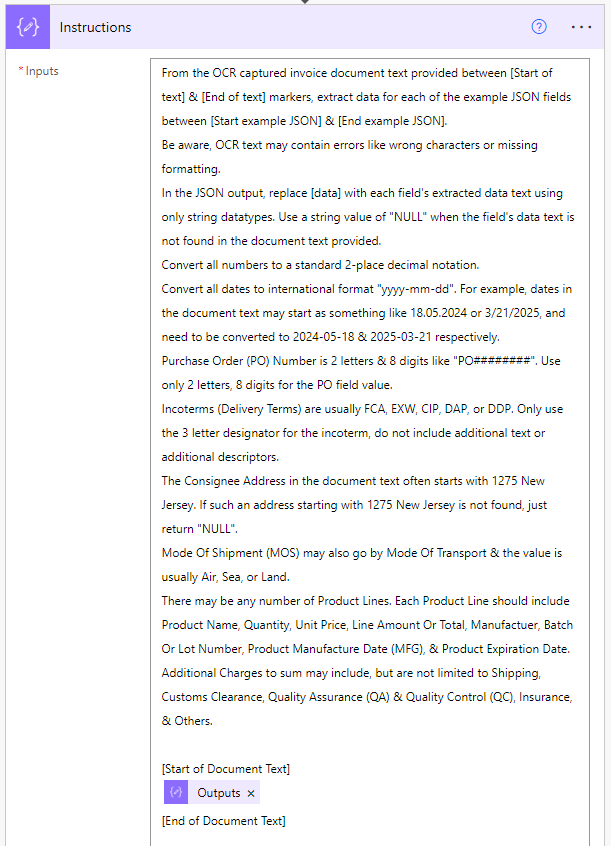
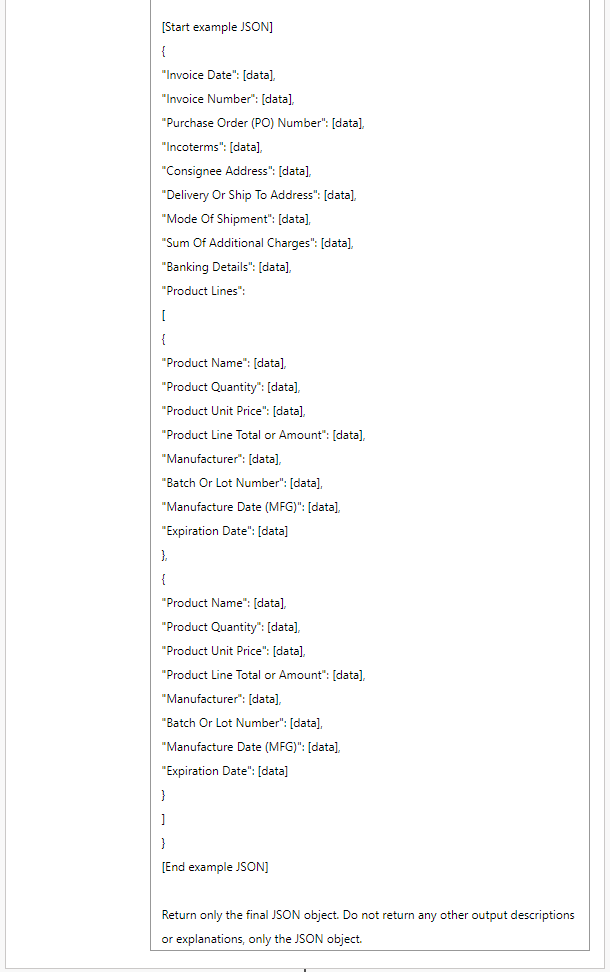
Which produced this output...

{
"Purchase Order Date": "2022-09-20",
"Purchase Order (PO) Number": "PO10022556",
"Requisition Order (RO) Number": "NULL",
"Incoterms": "DAP",
"Payment Terms": "NULL",
"Supplier": "[Redacted]",
"Chemonics Address": "[Redacted]",
"Consignee Address": "[Redacted]",
"Delivery Or Ship To Address": "[Redacted]",
"Mode Of Shipment": "Air",
"Description Of Goods": "NULL",
"Sum Of Additional Charges": "NULL",
"Product Lines": [
{
"Product Name": "KIT COBAS 58/68/8800 LYS",
"Product Quantity": "49",
"Product Unit Price": "213.00",
"Product Line Total or Amount": "10,437.00",
"Batch Or Lot Number": "J11051",
"Manufacture Date (MFG)": "2024-05-31",
"Expiration Date": "2024-05-31"
},
{
"Product Name": "KIT COBAS 58/68/8800 MGP",
"Product Quantity": "165",
"Product Unit Price": "50.00",
"Product Line Total or Amount": "8,250.00",
"Batch Or Lot Number": "J07927",
"Manufacture Date (MFG)": "2024-03-31",
"Expiration Date": "2024-03-31"
},
{
"Product Name": "KIT COBAS 6800/8800 HIV 96T",
"Product Quantity": "5",
"Product Unit Price": "838.95",
"Product Line Total or Amount": "4,194.75",
"Batch Or Lot Number": "H27735",
"Manufacture Date (MFG)": "2023-09-30",
"Expiration Date": "2023-09-30"
},
{
"Product Name": "KIT COBAS 6800/8800 HIV 96T",
"Product Quantity": "313",
"Product Unit Price": "838.95",
"Product Line Total or Amount": "262,591.35",
"Batch Or Lot Number": "H27745",
"Manufacture Date (MFG)": "2023-09-30",
"Expiration Date": "2023-09-30"
},
{
"Product Name": "KIT COBAS 6800/8800 HIV 96T",
"Product Quantity": "65",
"Product Unit Price": "838.95",
"Product Line Total or Amount": "54,531.75",
"Batch Or Lot Number": "H33673",
"Manufacture Date (MFG)": "2023-09-30",
"Expiration Date": "2023-09-30"
},
{
"Product Name": "KIT COBAS HBV/HCV/HIV-1",
"Product Quantity": "72",
"Product Unit Price": "290.00",
"Product Line Total or Amount": "20,880.00",
"Batch Or Lot Number": "H35037",
"Manufacture Date (MFG)": "2024-01-31",
"Expiration Date": "2024-01-31"
}
]
}
And remember you can always adjust the prompt to extract the different data you want on different documents & adjust how you want the data to be represented in the output. You can also often improve the output with more data specifications like "A PO number is always 2 letters followed by 8 digits. Only return those 2 letters & 8 digits."
Also if you are working with some Word/.docx files, there are built in OneDrive actions to convert them to .pdf files. So you should be able to process PDF, Image, and/or Word documents on the same type of set-up.
Also if you need something that can handle much larger files with a better page text filter/search set-up & larger GPT context window, check out this Query Large PDFs With GPT RAG template.
Remember, you may need AI Builder credits for the OCR & GPT actions in the flow to work. Each Power Automate premium licenses already come with 5000 credits that can be assigned to your environment. Depending on your license & organization, you may already have a few credits assigned to the environment.
If you are new, you can get a trial license to test things out: https://learn.microsoft.com/en-us/ai-builder/administer-licensing
Thanks for any feedback,
Please subscribe to my YouTube channel (https://youtube.com/@tylerkolota?si=uEGKko1U8D29CJ86).
And reach out on LinkedIn (https://www.linkedin.com/in/kolota/) if you want to hire me to consult or build more custom Microsoft solutions for you.
Also if you find my free builds/templates helpful, note they are often a by-product of work I do with a USAID contractor.
Version 1.8 adds a PageNumbers compose action that allows one to input specific pages of a PDF or image packet to pass on to the text conversion & GPT prompt. This could be useful for scenarios where the relevant data is always on the 1st couple of pages or for scenarios where one must filter to only the relevant pages/images because the full packet of PDF page data or image data would exceed the GPT prompt token / character limit.
Version 2 redesigns the Convert to txt section of the flow to use several clever Select actions & expressions to avoid an additional level of Apply to each looping. So for an example 3 page document with 50 lines per page, instead of taking 15-20 seconds and 156 action calls, it takes 1 second and 21 action calls to create the text replica document.
This makes the entire flow 2X faster (15 seconds vs. 30 seconds) and 7X more efficient for daily action limits.
This makes some use-cases like real-time processing on a Power Apps document upload or processing of larger batches of documents each day much more viable.
Version 2.5 More changes to the Convert to txt component to create a little more accurate text replicas and a change to the placeholder prompt to make the message a little more concise & more accurate. Also moved the spaces & line-break into a single Compose called StaticVariables & changed the variable name to the now more accurate EachPage.
The Convert to txt piece now calculates the minimum X coordinate so it can subtract that number from all X coordinates & thus remove additional spaces on the left margin, helping to reduce the characters fed to the GPT prompt.
The Convert to txt piece also now has a ZoomX parameter in the StaticPageVariables action which sets the spaces multiple, or the number of spaces, per coordinate point. So for example, 200=More Accurate Text Alignment, but 100=Less GPT Tokens. So there may be some trade-offs here. (The recognize text bounding box coordinates around longer pieces of text seem to be dis-proportionatly larger than on smaller pieces of text & mess up the text alignment for rows/lines with multiple boxes / text entries.)
In addition, the Convert to txt piece will now include line-breaks for blank Y coordinate rows/lines to more accurately replicate the vertical spacing of pieces of text. I figured since each line should be just a line-break character, it shouldn't add much to the character / token count for the GPT prompt.
So overall 2.5 adds some better options for increased extraction accuracy or for decreased characters/tokens per page & thus for slightly larger file capacity.
Version 2.7 Another adjustment to the conversion from OCR coordinates to the text (txt) replica.
It now calculates the X coordinates of a piece of text from the mid-point between X coordinates 0 & 1. So along with the Y coordinates that were already being calculated from the mid-point between Y coordinates 0 & 3, this now registers the position of each piece of text from the center point of each coordinates box.
I also set it to start using an estimate of the length of text characters instead of the length of the overall coordinates box to calculate the whitespace / number of spaces between each piece of text.
Overall this makes this set-up even more accurate, improving text alignment, improving performance on more tilted pages, & adjusting the spacing/alignment for different font / text sizes on the same line.
Microsoft started requiring approval actions after every GPT action. If you want to get around this requirement, see this post on setting the approval step to automatically succeed & move to the next action.
Version 2.9 Adjustment For New MS Approval Requirement & Adjust Retry Policy
I added in the automatic approval step to get around the new MS approval action requirement. I also set the retry policy on the GPT action to retry every 5 seconds up to 7 times so it will fail less if wrongful 429 too many request errors occur.
Microsoft is deprecating the original Create text with GPT action this template relies on.
Users may need to use the new “Create text with GPT using a prompt” action & create a custom prompt on that action instead.
https://learn.microsoft.com/en-us/ai-builder/use-a-custom-prompt-in-flow
The ExtractPDFImageDataWithGPT_1_0_0_x Power Apps solution package contains a version of the flow with the new action.
Version 3.1 Solution Import
Solutions can now include data models / prompt models so I was able to update the flow in the Solution import to use the new prompt action.
I also was able to adjust the EachPage variable set-up so if anyone needs to put this workflow inside a loop to process multiple files at once, they can now turn concurrency on & process them in parallel.
03-26-2025 Now also includes an Auto Rotate version of the flow showing how to set the flow up to ensure all OCR text data is up-right, this helps in-case some of your pages were rotated with text at 90, 180, or 270 degrees.
Legacy Power Automate Import: https://drive.google.com/file/d/1gyC6AK3ur0rcE1UwDK85qInwTRTeoAFU/view?usp=sharing (Not Recommended)
Solution Zip Download Link: https://drive.google.com/file/d/11t6M2u-qgGrQh9GbJ2ocpeUbSnSO_raL/view?usp=sharing (Recommended. Should import the AI Hub Prompt that uses one of the most recent LLM models.)
Go to the Power Apps home page (https://make.powerapps.com/). Select Solutions on the left-side menu, select Import solution, Browse your files & select the ExtractPDFImageDataWithGPT_1_0_0_x.zip file you just downloaded. Then select Next & follow the menu prompts to apply or create the required connections for the solution flows. And finish importing the solution.
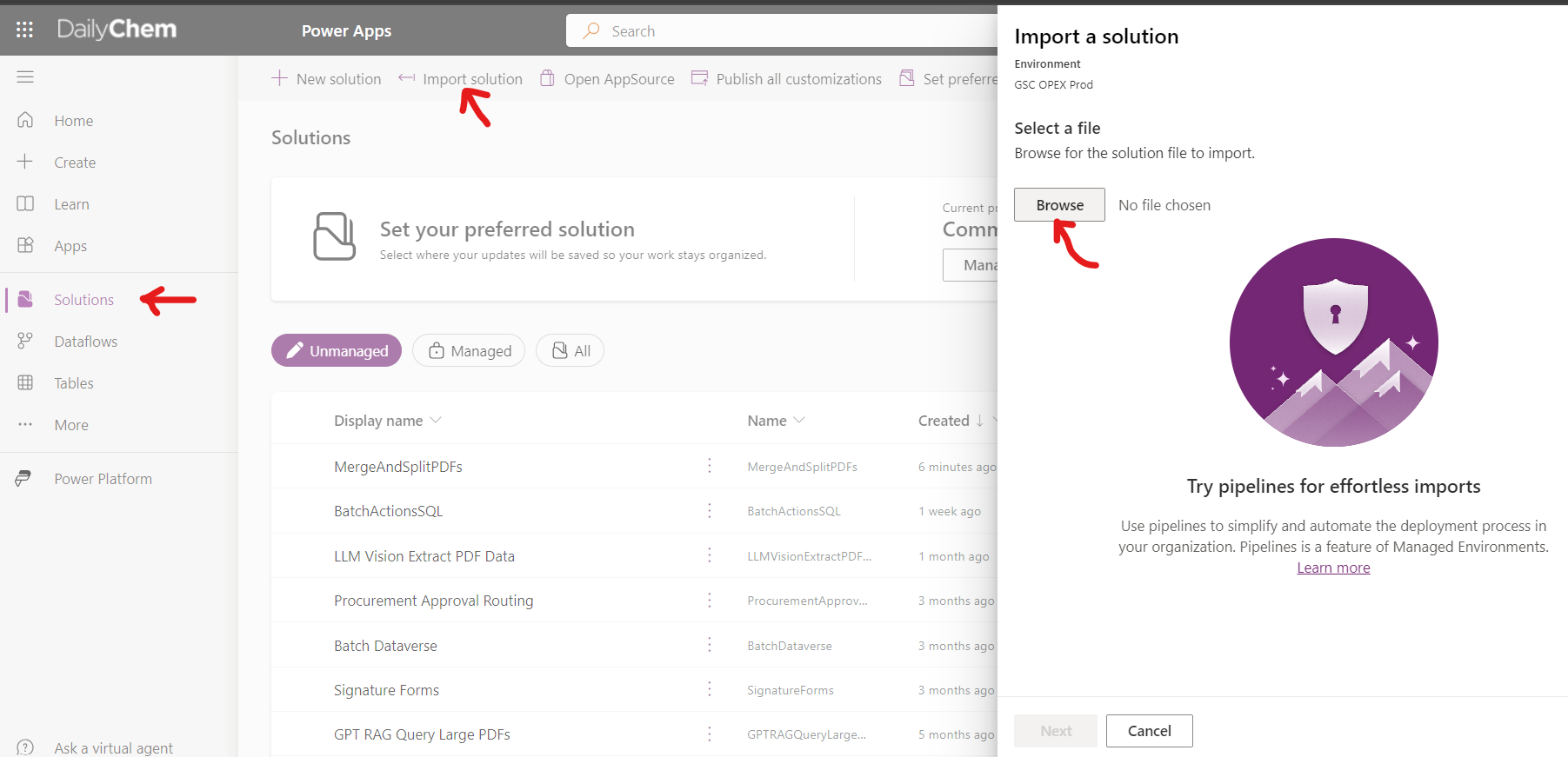
Once the solution is done importing, select the solution name in the list at the center of the screen. Once inside the solution click on the 3 vertical dots next to the flow name of the latest version & select edit to enter the flow.
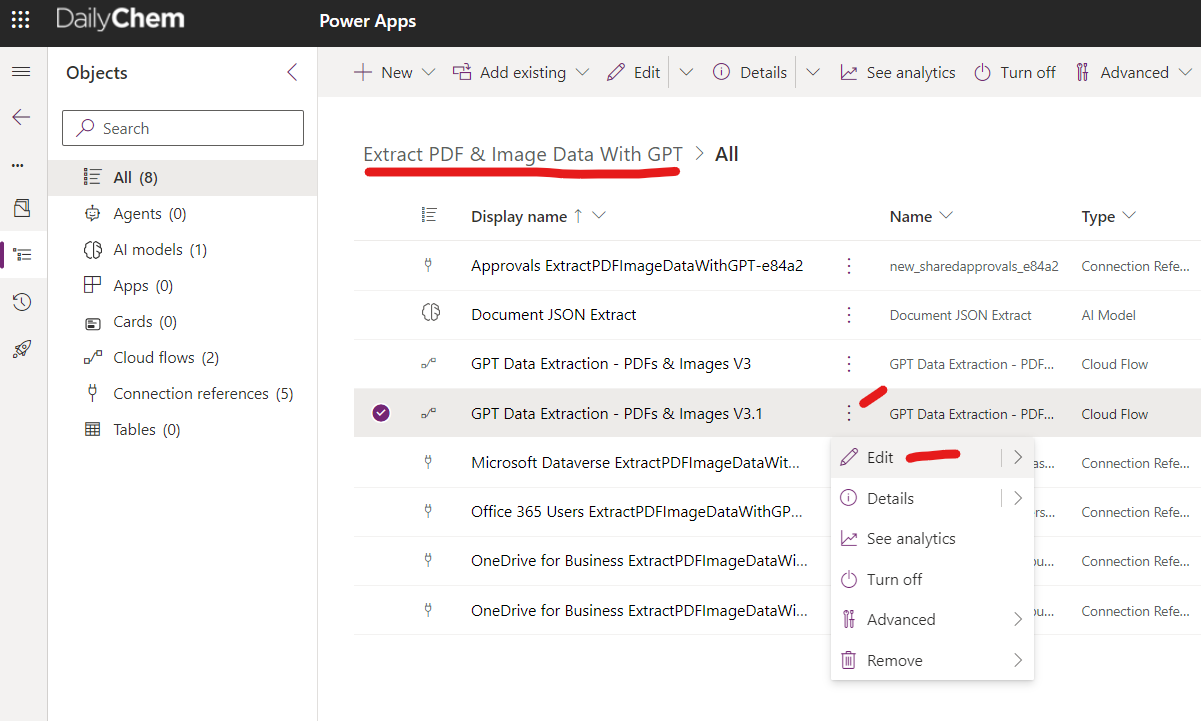
Solution Zip Download Link: https://drive.google.com/file/d/1fN1eQfrKfdYfa0LH4uKadqcxifXUXrs3/view?usp=sharing (Recommended import) (MS forums are broken, I can't remove outdated attachments below)



